mysql总结
网络摘录
InnoDB引擎表的一些关键特征
- InnoDB引擎表是基于B+树的索引组织表(IOT)
- 每个表都有一个聚集索引(clustered index)
- 所有的行记录都存储在B+树的叶子节点(leaf pages of the tree)
- 基于聚集索引的增、删、改、查的效率相对是最高的
- 如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择其作为聚集索引
- 如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引
- 如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高
- 使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致
- 该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致
- 除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差
实际情况是如何呢?经过简单 TPCC基准测试 ,修改为使用自增列作为主键与原始表结构分别进行TPCC测试,前者的TpmC结果比后者高9%倍,足见使用自增列做InnoDB表主键的明显好处,其他更多不同场景下使用自增列的性能提升可以自行对比测试下。
ACID
- 关系数据库的ACID模型拥有 高一致性 + 可用性 很难进行分区:
- Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
- Consistency一致性. 在事务开始或结束时,数据库应该在一致状态。
- Isolation隔离层. 事务将假定只有它自己在操作数据库,彼此不知晓。
- Durability. 一旦事务完成,就不能返回。
OLTP OLAP
百万级的数据,无论侧重OLTP还是OLAP,当然就是MySql了。
过亿级的数据,侧重OLTP可以继续Mysql,侧重OLAP,就要分场景考虑了
实时计算场景:强调实时性,常用于实时性要求较高的地方,可以选择Storm;
批处理计算场景:强调批处理,常用于数据挖掘、分析,可以选择Hadoop;
实时查询场景:强调查询实时响应,常用于把DB里的数据转化索引文件,通过搜索引擎来查询,可以选择solr/elasticsearch;
企业级ODS/EDW/数据集市场景:强调基于关系性数据库的大数据实时分析,常用于业务数据集成,可以选择Greenplum;
数据库系统一般分为两种类型:
一种是面向前台应用的,应用比较简单,但是重吞吐和高并发的OLTP类型;
一种是重计算的,对大数据集进行统计分析的OLAP类型。
传统数据库侧重交易处理,即OLTP,关注的是多用户的同时的双向操作,在保障即时性的要求下,系统通过内存来处理数据的分配、读写等操作,存在IO瓶颈。
OLTP(On-Line Transaction Processing,联机事务处理)系统也称为生产系统,它是事件驱动的、面向应用的,比如电子商务网站的交易系统就是一个典型的OLTP系统。OLTP的基本特点是:
数据在系统中产生;
基于交易的处理系统(Transaction-Based);
每次交易牵涉的数据量很小;
对响应时间要求非常高;
用户数量非常庞大,主要是操作人员;
数据库的各种操作主要基于索引进行。
分析型数据库是以实时多维分析技术作为基础,即侧重OLAP,对数据进行多角度的模拟和归纳,从而得出数据中所包含的信息和知识。
OLAP(On-Line Analytical Processing,联机分析处理)是基于数据仓库的信息分析处理过程,是数据仓库的用户接口部分。OLAP系统是跨部门的、面向主题的,其基本特点是:
本身不产生数据,其基础数据来源于生产系统中的操作数据(OperationalData);
基于查询的分析系统;
复杂查询经常使用多表联结、全表扫描等,牵涉的数据量往往十分庞大;
响应时间与具体查询有很大关系;
用户数量相对较小,其用户主要是业务人员与管理人员;
主键使用自增主键的好处
- InnoDB数据是按照主键聚簇的,数据在物理上按照主键大小顺序存储,使用其他列或者组合无法保证顺序插入,随机IO(SSD的话影响不大)导致插入性能下降。
- 习惯统一,语义无关
- a.自增型主键以利于插入性能的提高;
- b.自增型主键设计(int,bigint)可以降低二级索引的空间,提升二级索引的内存命中率;
- c.自增型的主键可以减小page的碎片,提升空间和内存的使用。
在InnoDB表中按主键顺序插入行
- 如果正在使用InnoDB表并且没有什么数据需要聚集,那么可以定义一个代理键作为主键,这种主键的数据应该和应用无关,最简单的方法是使用auto_increment自增列。这样可以保证数据行是按照顺序写入,对于根据主键做关联操作的性能也会更好。
- 最好避免随机的聚簇索引,特别对于I/O密集型的应用。例如,从性能的角度考虑,使用UUID作为聚簇索引会很糟糕:它使得聚簇索引的插入变得完全随机,这是最坏的情况,使得数据没有任何聚集特性。通过测试,向UUID主键插入行不仅花费的时间更长,而且索引占用的空间也更大。这一方面是由于主键字段更长,另一方面毫无疑问是由于页分裂和碎片导致的。
- 这是由于当主键的值是顺序的,则InnoDB把每一条记录都存储在上一条记录的后面。当达到页的最大填充因子时(InnoDB默认的最大填充因子是页大小的15/16,留出的部分空间用于以后修改),下一条记录就会写入新的页中。一旦数据按照这样顺序的方式加载,主键页就会近似于被顺序的记录填满,这也是所期望的结果。
而当采用UUID的聚簇索引的表插入数据,因为新行的主键值不一定比之前的插入值大,所以InnoDB无法简单的总是把新行插入到索引的最后,而是需要为新的行寻找合适的位置—-通常是已有数据的中间位置—-并且分配空间。这会增加很多额外的工作,并导致数据分布不够优化。下面是总结的一些缺点:
- 写入目标页可能已经刷到磁盘上并从缓存中移除,或者是还没有被加载到缓存中,InnoDB在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机I/O;
- 因为写入是乱序的,InnoDB不得不频繁的做页分裂操作,以便为新的行分配空间。页分裂会导致移动大量数据,一次插入最少需要修改三个页而不是一个页。
- 由于频繁的页分裂,页会变得稀疏并被不规则的填充,所以最终数据会有碎片。
- 把这些随机值载入到聚簇索引以后,需要做一次optimize table来重建表并优化页的填充。
注意:顺序主键也有缺点:对于高并发工作负载,在InnoDB中按主键顺序插入可能会造成明显的争用。主键的上界会成为“热点”。因为所有的插入都发生在这里,所以并发插入可能导致间隙锁竞争。另一个热点可能是auto_increment锁机制;如果遇到这个问题,则可能需要考虑重新设计表或者应用,或者更改innodb_autonc_lock_mode配置。
技术内幕innoDB读书笔记
##1. 聚簇索引
- 术语“聚族”表示数据行和相邻的键值紧凑的存储在一起。因为无法同时把数据行放在两个不同的地方,所以一个表只能有一个聚族索引。
- 一个表只能由一个聚簇索引
聚簇索引优点
- 可以把相关数据保存在一起。例如实现电子邮件时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚族索引,则每封邮件都可能导致一次磁盘I/O;
- 数据访问更快。聚族索引将索引和数据保存在同一个B-Tree中,因此从聚族索引中获取数据通常比在非聚族索引中查找更快。
- 使用覆盖索引扫描的查询可以直接使用节点中的主键值。
聚簇索引缺点
- 聚簇数据最大限度的提高了I/O密集型应用的性能,但如果数据全部都放在内存中,则访问的顺序就没有那么重要了,聚簇索引也就没有那么优势了;
- 插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用OPTIMIZE TABLE命令重新组织一下表。
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置。
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂”的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次分裂操作。页分裂会导致表占用更多的磁盘空间。
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
- 二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。
- 二级索引访问需要两次索引查找,而不是一次。
##2. 存储引擎
- 存储引擎负责实现索引
- innoDB、MyISAM
- 存储引擎是基于表的,而不是基于数据库
- mysql插件式体系结构,可以按需选择建立不同的存储引擎表
- 对于开发人员来说,存储引擎是透明的,对于DBA来说,mysql的核心是存储引擎
innoDB
- 行锁
- 支持外键
- 默认不锁读,多版本并发控制(MVCC)获得高并发性
- 每张表都按主键的顺序存放,如果没有显示的指定,innoDB会自动生成ROWID,并以此为主键
MyISAM
- 不支持事物
- 表锁
- 全文索引
NDB
- share nothing
- 数据全部放入内存
- 主键查询速度极快
- 添加NDB Data Node 可以线性提高性能
- 高可用,高性能的集群系统
- 问题是join操作是mysql数据库层完成的而不是存储引擎。意味着巨大的网络开销,因此查询速度慢。
Memory
- 全部内存,不容灾
- 适用于临时表
- 默认哈系索引而不是B+树
- 只支持表锁,并发性能差
- 不支持text,blob
- 变长字段(varchar)也是按照定长字段(char)存,浪费内存
Archive
- 只支持insert和select
- zlib算法压缩行(row),压缩比1:10
- 适合存储归档数据,如日志信息。
- 行锁,支持高并发插入
- 非事物安全
mysql 支持全文索引(MyISAM引擎)
MyISAM不支持事物,但是innoDB支持
连接mysql 进程通信方式,管道、TCP/IP、Unix域名套接字
- TCP/IP 网络
- 管道、Unix域套接字 本机
innoDB 关键特性
插入缓冲
- 对于非聚集类索引的插入和更新操作,不是每一次都直接插入到索引页中,而是先插入到内存中。具体做法是:如果该索引页在缓冲池中,直接插入;否则,先将其放入插入缓冲区中,再以一定的频率和索引页合并,这时,就可以将同一个索引页中的多个插入合并到一个IO操作中,大大提高写性能。
- 其使用满足两个条件 1)索引是辅助索引 2)索引不是唯一的(不然内存中的数据和文件中的数据不能保证唯一性,两份数据)
- 这个设计思路和HBase中的LSM树有相似之处,都是通过先在内存中修改,到达一定量后,再和磁盘中的数据合并,目的都是为了提高写性能
- 回忆一下在《MySQL - 浅谈InnoDB存储引擎》中提到的master thread主循环其中的一项工作就是每秒中合并插入缓冲(可能)。
两次写
- 相对于插入缓冲带给innoDB的是性能,两次写则是可靠性
- 它的作用不是还原数据,而是保证不会丢失修改
- 因为innoDB是逻辑日志记录,但是恢复的时候也要基于页面是完整页,两次写保证先写缓冲在写文件,避免写坏页没有备份
自适应哈希索引
- 类似于查询条件缓存(只支持=)
- 数据库自适应,无需人工干预,可配置关闭
mysql 日志文件
- 错误日志(err_log)
- 二进制日志(bin_log)
- 慢查询日志(slow_log)
- 查询日志(query_log)
第五章-索引与算法
5.1 innoDB存储索引概述
支持两种常见的索引
- B+树索引
- 哈希索引(自适应)
B+树
- (B代表的不是二叉(binary),而是代表平衡(balance)),B+树是从最早的平衡二叉树演化而来,但不是一个二叉树
- B+树索引并不能找到一个给定键值的具体行,而至能找到查找数据行所在的页,然后数据库把页读入内存,再在内存中查找数据。
5.2 二分查找法
- 也称折半查找法,用来查找一组有序记录数组中的某一记录。
- 基本思想是:将记录有序化(递增或递减)排列,查找过程中采用跳跃式方式查找,即有序数列中点位置开始比较,小于查左半,大于查右半。一次比较,查找区间缩小一半。
- 每页Page Directory中的槽是按照主键的顺序存放的,对于某一条具体记录的查询是通过对Page Directory进行二分查找得到的。
5.3 平衡二叉树
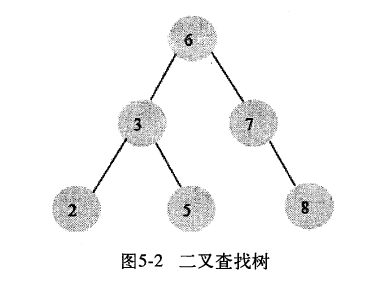
图5-2的平均查找次数(3+3+2+2+1)/6=2.3次。比顺序查找快(1+2+3+4+5+6)/6=3.3
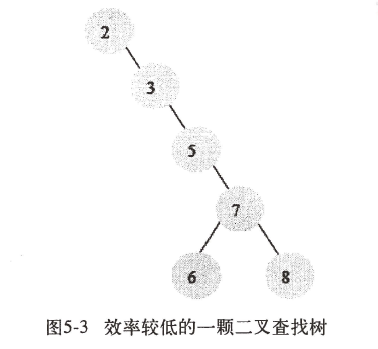
图5-3的平均查找次数(1+2+3+4+5+6)/6=3.16次,和顺序查找差不多。效率就低了。
- 因此若想最大性能的构造一个二叉查找树,需要树是平衡的,引出新的定义-平衡二叉树(AVL树)。
- AVL树,左右两个子树高度差最大为1。
- AVL树查询速度很快,但是维护成本非常大,通常需要1次或多次左旋和右旋来维护插入或更新后的平衡。
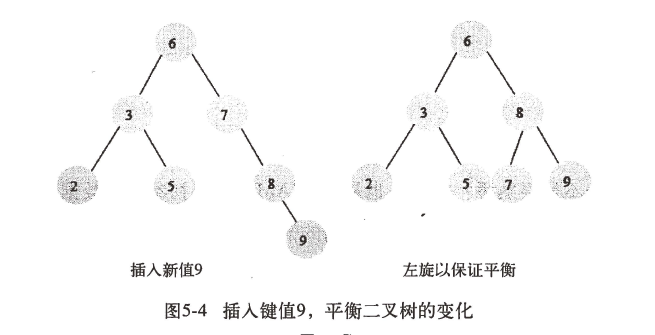
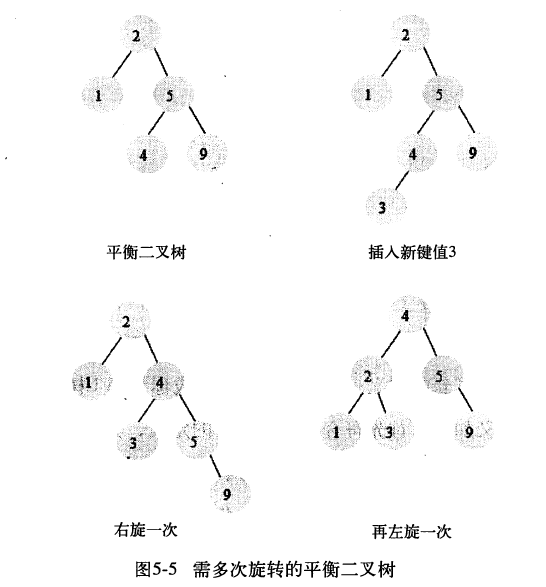
图5-4和5-5例举了一颗AVL树插入一个新节点,需要做的旋转操作(具有一定开销)。更新、删除同理。AVL树多用于内存结构对象中,因此开销又相对较小。
5.4 B+树
- 为磁盘或者其他直接存储设备设计的一种平衡查找树
- 所有记录节点都是按键值的大小顺序存放在同一层叶子节点中
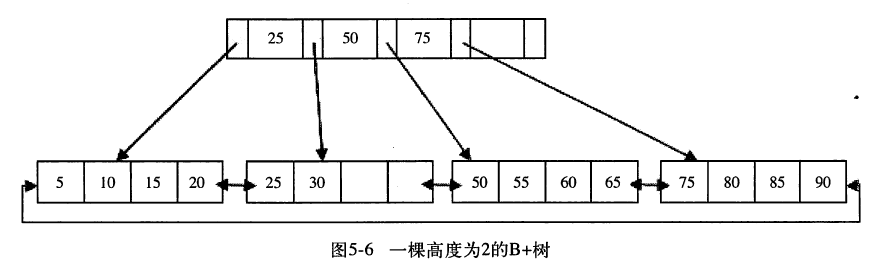
图5-6 为一个B+树,其高度为2,每页可存放4条记录,扇出(fan out)为5,所有记录都在叶子节点中,且顺序存放。
5.4.1 B+树插入操作

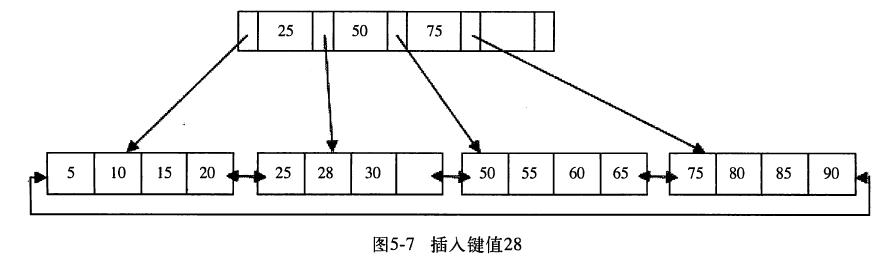
当前Leaf Page和Index Page 都没满,直接插入
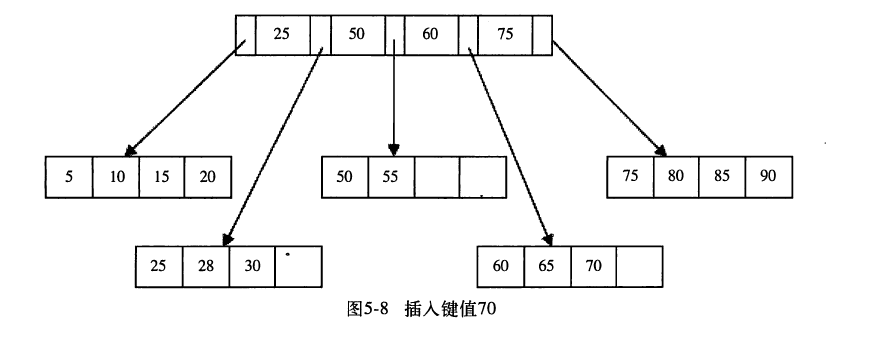
Leaf Page已经满了,Index Page没有慢,符合表5-1第二种,这时插入Leaf Page后的情况是50,55,60,65,70,根据中间值60拆分叶子节点,可得图5-8。
最后表5-1第三种比较复杂,插入95,为了保持平衡,对于新插入的键值可能要做大量的拆分页(split)操作,而B+树主要用于磁盘,所以会有很多磁盘操作,为了减少拆分,B+树提供旋转(rotation)的功能。
5.4.2 B+树删除操作
5.5 B+树索引
- B+树索引的本质就是B+树在数据库中的实现。
- 高扇出性,在数据库中B+输得高度一般都在2-3层,也就是说查找某一键值的行记录,最多只需要2-3次IO。
- 分为聚集索引(clustered index)和辅助聚集索引(secondary index),区别在于叶节点是否存一整行的信息。
5.5.1 聚集索引
5.5.1 辅助索引(非聚集索引)
- 叶节点除了包含键值,还有一个书签(bookmark),书签告诉innoDB存储引擎哪里找到索引对应的行数据。
- 辅助索引不影响聚集索引的组织。每张表上可有多个辅助索引。
- 通过辅助索引查数据,遍历辅助索引通过叶级别的指针获得指向主键索引的主键,然后通过主键索引找到完整记录。
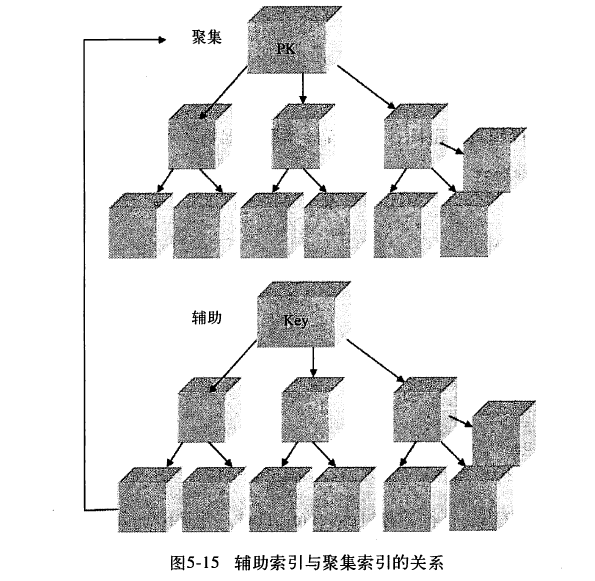
举例来说,如果在一棵高度为3的辅助索引树中查找数据,那么需要遍历3次辅助树找到主键,然后如果聚集索引高度同样为3,
那么还需要对聚集索引进行3次查找,才能最终找到一个完整的行数据所在的页。因此一共需要6次逻辑IO。